一、基于时间戳的CDC
1、原理
根据自增id 和 插入/更新时间戳(create_time,update_time)判断是否为新增记录。
所以,通常需要建立一个额外的数据库表存储上一次更新时间或上一次抽取的最后一个序列号。
2、优缺点
基于时间戳和自增序列的方法是CDC最简单的实现方式,也是最常用的方法,但它的缺点也很明显,主要如下:
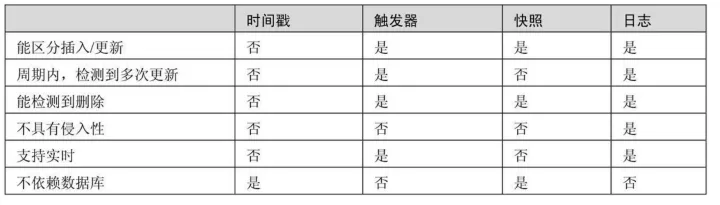
- 不能区分插入和更新操作。只有当源系统包含了插入时间戳和更新时间戳两个字段,才能区别插入和更新,否则不能区分
- 不能记录删除记录的操作。不能捕获到删除操作,除非是逻辑删除,即记录没有被真的删除,只是做了逻辑上的删除标志。
- 无法识别多次更新。如果在一次同步周期内,数据被更新了多次,只能同步最后一次更新操作,中间的更行操作都丢失了。
- 不具有实时能力。时间戳和基于序列的数据抽取一般适用于批量操作,不适合于实时场景下的数据抽取。
二、基于触发器的CDC
1、原理
当执行INSERT、UPDATE、DELETE这些SQL语句时,可以激活数据库里的触发器(所以所有的变更都可以被捕捉到),并执行一些动作,就是说触发器可以用来捕获变更的数据并把数据保存到中间临时 表里。然后这些变更的数据再从临时表中取出,被抽取到数据仓库的过渡区里。
作为直接在源数据库上建立触发器的替代方案,可以使用源数据库的复制功能,把源数据库上的数据复制到备库上,在备库上建立触发器以提供CDC功能。尽管这种 方法看上去过程冗余,且需要额外的存储空间,但实际上这种方法非常有效,而且没有侵入性。复制是大部分数据库系统的标准功能,如MySQL、Oracle和SQL Server等都 有各自的数据复制方案
2、优缺点
大多数场合下,不允许向操作型数据库里添加触发器(业务数据库的变动通常都异常慎重),而且这种方法会降低系统的性能,所以此方法用的并不是很多
三、基于快照的CDC
1、原理
快照就是一次性抽取源系统中的全部数据,把这些数据装 载到数据仓库的过渡区中。下次需要同步时,再从源系统中抽取全部数据,并把这些全部数据也放到数据仓库的过渡区中,作为这个表的第二个版本,然后再比较这两个 版本的数据,从而找到变化。
有多个方法可以获得这两个版本数据的差异。假设表有两个列id和name,id是主键列。该表的第一、第二个版本的快照表名为snapshot_1、snapshot_2。下面的SQL语句
select * from
(select case when t2.id is null then 'D'
when t1.id is null then 'I'
when t1.name <> t2.name then 'U'
else 'N' end as flag,
case when t2.id is null then t1.id
else t2.id end as id,
t2.name
from snapshot_1 t1 full outer join snapshot_2 t2
on t1.id = t2.id) a
where flag <> 'N';在主键id列上做全外链接,并根据主键比较的结果增加一个标志字段,I表示新增,U表示更新,D代表删除,N代表没有变化。外层查询过滤掉没有变化的记录。
⭕️ 虽然可以捕捉到增、删、改的变化,但还是无法识别多次更新
2、优缺点
- 基于快照的CDC可以检测到插入、更新和删除的数据,这是相对于基于时间戳的CDC方案的优点
- 它的缺点是需要大量的存储空间来保存快照
另外,当表很大时, 这种查询会有比较严重的性能问题
四、基于日志的CDC(binlog)
1、原理
最复杂的和最没有侵入性的CDC方法是基于日志的方式。数据库会把每个!插入、更新、删除操作记录到日志里。如使用MySQL数据库,只要在数据库服务器中启用二进制日志(设置log_bin服务器系统变量),之后就可以实时从数据库日志中读取到所有数据库写操作,并使用这些操作来更新数据仓库中的数据。这种方式需要把二进制 日志转为可以理解的格式,然后再把里面的操作按照顺序读取出来。
2、优缺点
使用基于数据库的日志工具也有缺陷,即只能用来处理一种特定的数据库,如果要在异构的数据库环境下使用基于日志的CDC方法,就要使用Oracle GoldenGate之类的商业软件。
五、四种抽取方法的对比