通常情况下,将数据源中不完整、重复以及错误等有问题的数据称为“脏”数据。由于数据仓库的数据来自底层数据源,因此“脏”数据出现的原因与数据源有密切的关系。基于数据源的“脏”数据分类如图所示。
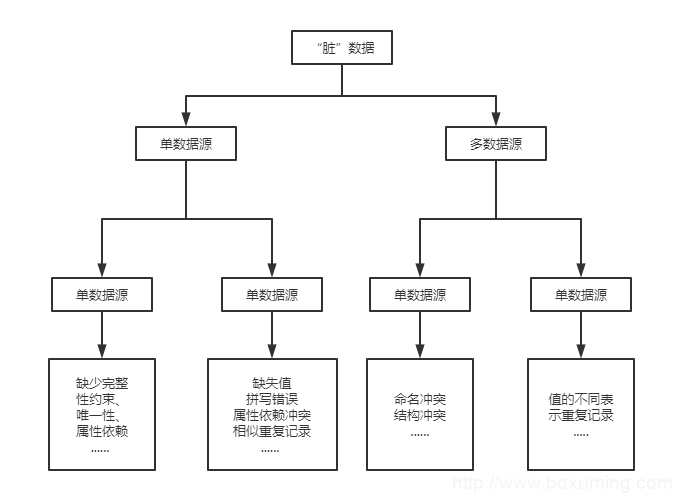
图1基于数据源的“脏”数据分类
从图1中可以看出,基于数据源的“脏”数据质量问题可以分为两类,即单数据源问题和多数据源问题。单数据源问题和多数据源问题的具体介绍如下。
(1)单数据源问题
单数据源的数据质量主要取决于它的模式对数据完整性约束的控制程度。由于数据模式和完整性约束控制了数据的范围,如果单数据源没有数据模式,就会对进入和存储的数据。
缺乏相应的限制,此时很有可能出现拼写错误的数据和不一致的数据。
单数据源的实例层问题是由于数据在模式层无法预防的错误和不一致引起的。典型的单数据源实例层问题包括缺失值(即一些记录在某些属性上没有值)、拼写错误(即在数据输入时容易出现)、属性依赖冲突(即不满足属性间的依赖关系,如城市名与邮政编码不满足对应关系等)以及相似重复记录(即由于数据输入错误等原因导致有多条记录表示现实世界中的同一个实体)。
对于不同范围的数据质量问题,相应的数据清洗方式也会有所不同,清楚地了解目标数据存在的质量问题是提供完善的数据清洗方式的基础。
(2)多数据源问题
单数据源情况下出现的问题在多数据源情况下变得更加严重。每个数据源中都有可能包含“脏”数据,而且每个数据源中的数据表示方法都各自不同,还有可能出现数据重复或矛盾冲突。因为在很多情况下,各个数据源都是为了满足某一个特定需要而单独设计、配置和维护,这很大程度上导致数据库管理系统、数据模型、模式设计和实际数据的异构性。多数据源中存在的与模式相关的质量问题主要是名字冲突和结构冲突。名字冲突表现在同一个名字表示不同的对象,或不同的名字表示同一个对象;结构冲突的典型表现是不同的数据源中同一对象用不同的方式表示。
除模式相关的质量问题外,许多质量问题只出现在实例层次上。单数据源中出现的各种问题都将以不同方式出现在不同的数据源中,如重复记录、矛盾记录等。即使在具有相同属性名称和数据类型的情况下,各异构数据源中的数据也可能有不同的表示方式,或不同的解释在不同的数据源中信息的聚集程度以及代表的时间点都有可能不同。

