聚集索引
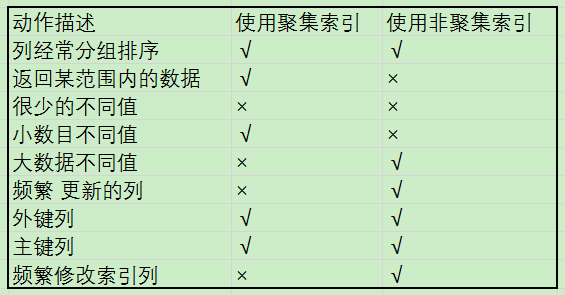
聚集索引的作用对象是一张表数据的物理地址,聚集索引使得数据按照物理地址顺序的存储在存储介质中,数据的物理地址也是连续的,因此聚集索引是查询速度最快的索引,其查询原理是二分法。
聚集索引尽量建立在值不会发生变更的列上,否则会带来非聚集索引的维护。一般来说这个索引建立在ID列上,而该ID则一般赋予一个自增的属性。这样做的意义和好处是当向表中插入一条ID序号靠前的数据时,不会因为插入一条数据,而移动整个数据集合的物理地址。
尽量在建立非聚集索引之前建立聚集索引,否则会导致表上所有非聚集索引的重建,聚集索引应该避免建立在数值单调的列上,否则可能会造成IO的竞争,以及B树的不平衡,从而导致数据库系统频繁的维护B树的平衡性。聚集索引的列值最好能够在表中均匀分布
但是对于业务的角度上来说,自增的ID列往往是个相对来说没有意义的字段,而且聚集索引一个表中只能存在一个。所以这里又引入了一个非聚集索引的概念。
非聚集索引
非聚集索引定义的原则往往是基于业务逻辑。非聚集索引在物理地址上不相邻,更像是一个数据字典索引。
在使用非聚集索引时,首先通过一级索引字典查出来一个包含所需数据内容的数据块,一般是8K的数据块,而后遍历这个数据块找到所需数据。非聚集索引速度比聚集索引慢,但是一个表中非聚集可以建立多个。
非聚集索引又分唯一非聚集索引和非唯一两种,这同样是依据业务逻辑而定的,唯一非聚集索引指的是一个由多个业务字段组成的索引,在业务逻辑上是唯一的,反之就是非唯一的非聚集索引。比如“中国+身份证号”,这就是一个唯一索引,因为中国的每个身份证号理论上都是唯一的。而“中国+姓名”则是一个非聚集索引,因为中国又很多重名的人。
相比之下,唯一非聚集索引速度更快,这是因为查询过程中,一旦查到符合要求的数据,数据库会立刻停止查找,因为其是唯一的,继续查下去就没有意义了。反之,非唯一非聚集索引就会慢一些,因为即使查到了一条数据后,还要继续向后查找,因为本条数据在数据库中是非唯一的,仍然可能有其他索引字段相同的数据存在,所以查询开销会增加。
区别
聚集索引是一种物理排序规则,数据按照聚集索引列有序的排列,查询时根据数据查询范围即可直接定位数据内容。
非聚集索引是一种映射的数据字典,数据在物理空间中是乱序的,字典中存储了索引列的位置映射,在查询使先根据字典查询出数据所在的大致物理位置,再去相应的物理位置查询数据的具体内容。