语言作为人类的一种基本交流方式,在数千年历史中得到持续传承。近年来,语音识别技术的不断成熟,已广泛应用于我们的生活当中,成为人与机器通过自然语言交互重要方式之一。语音识别技术是如何让机器“听懂”人类语言?
随着计算机技术的飞速发展,人们对机器的依赖已经达到一个极高的程度。语音识别技术使得人与机器通过自然语言交互成为可能。最常见的情形是通过语音控制房间灯光、空调温度和电视的相关操作等。并且,移动互联网、智能家居、汽车、医疗和教育等领域的应用带动智能语音产业规模持续快速增长,2018年全球智能语音市场规模将达到141.1亿美元。
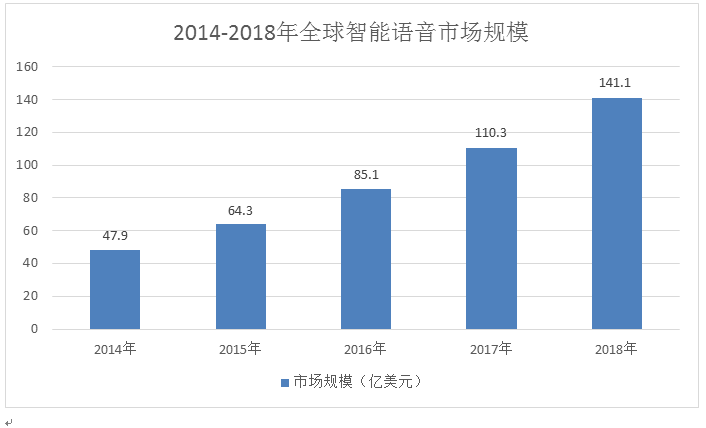
(数据来源:中商产业研究院整理)
目前,在全球智能语音市场占比情况中,各巨头市场占有率由大到小依次为:Nuance、谷歌、苹果、微软和科大讯飞等。
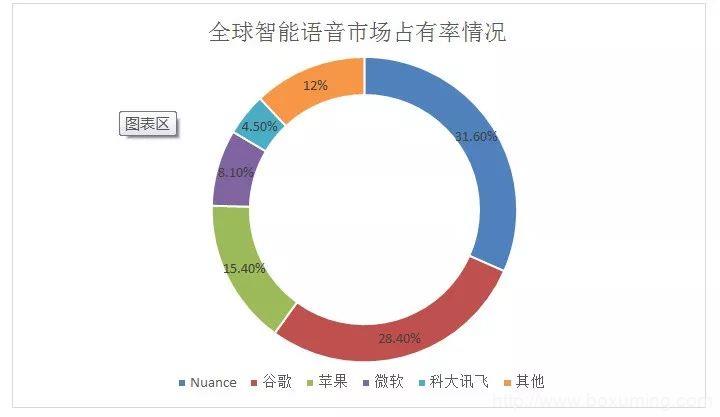
(数据来源:中商产业研究院整理)
语音识别的本质就是将语音序列转换为文本序列,其常用的系统框架如下:
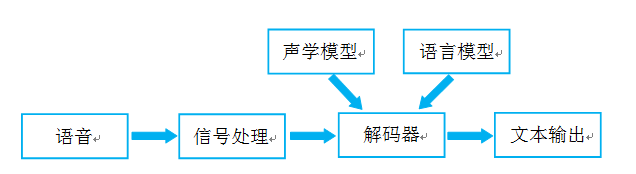
接下来对语音识别相关技术进行介绍,为了便于整体理解,首先,介绍语音前端信号处理的相关技术,然后,解释语音识别基本原理,并展开到声学模型和语言模型的叙述。
1.前端信号处理
前端的信号处理是对原始语音信号进行的相关处理,使得处理后的信号更能代表语音的本质特征,相关技术点如下表所述:
1、语音活动检测
语音活动检测(Voice Activity Detection, VAD)用于检测出语音信号的起始位置,分离出语音段和非语音(静音或噪声)段。VAD算法大致分为三类:基于阈值的VAD、基于分类器的VAD和基于模型的VAD。
基于阈值的VAD是通过提取时域(短时能量、短时过零率等)或频域(MFCC、谱熵等)特征,通过合理的设置门限,达到区分语音和非语音的目的;
基于分类的VAD是将语音活动检测作为(语音和非语音)二分类,可以通过机器学习的方法训练分类器,达到语音活动检测的目的;
基于模型的VAD是构建一套完整的语音识别模型用于区分语音段和非语音段,考虑到实时性的要求,并未得到实际的应用。
2、降噪
在生活环境中通常会存在例如空调、风扇等各种噪声,降噪算法目的在于降低环境中存在的噪声,提高信噪比,进一步提升识别效果。
常用降噪算法包括自适应LMS和维纳滤波等。
3、回声消除
回声存在于双工模式时,麦克风收集到扬声器的信号,比如在设备播放音乐时,需要用语音控制该设备的场景。
回声消除通常使用自适应滤波器实现的,即设计一个参数可调的滤波器,通过自适应算法(LMS、NLMS等)调整滤波器参数,模拟回声产生的信道环境,进而估计回声信号进行消除。
4、混响消除
语音信号在室内经过多次反射之后,被麦克风采集,得到的混响信号容易产生掩蔽效应,会导致识别率急剧恶化,需要在前端处理。
混响消除方法主要包括:基于逆滤波方法、基于波束形成方法和基于深度学习方法等。
5、声源定位
麦克风阵列已经广泛应用于语音识别领域,声源定位是阵列信号处理的主要任务之一,使用麦克风阵列确定说话人位置,为识别阶段的波束形成处理做准备。
声源定位常用算法包括:基于高分辨率谱估计算法(如MUSIC算法),基于声达时间差(TDOA)算法,基于波束形成的最小方差无失真响应(MVDR)算法等。
6、波束形成
波束形成是指将一定几何结构排列的麦克风阵列的各个麦克风输出信号,经过处理(如加权、时延、求和等)形成空间指向性的方法,可用于声源定位和混响消除等。
波束形成主要分为:固定波束形成、自适应波束形成和后置滤波波束形成等。
2.语音识别的基本原理
已知一段语音信号,处理成声学特征向量之后表示为,其中表示一帧数据的特征向量,将可能的文本序列表示为,其中表示一个词。语音识别的基本出发点就是求,即求出使最大化的文本序列。将通过贝叶斯公式表示为:
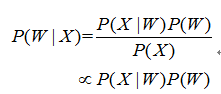
其中,称之为声学模型,称之为语言模型。大多数的研究将声学模型和语言模型分开处理,并且,不同厂家的语音识别系统主要体现在声学模型的差异性上面。此外,基于大数据和深度学习的端到端(End-to-End)方法也在不断发展,它直接计算 ,即将声学模型和语言模型作为整体处理。本文主要对前者进行介绍。
3.声学模型
声学模型是将语音信号的观测特征与句子的语音建模单元联系起来,即计算。我们通常使用隐马尔科夫模型(Hidden Markov Model,HMM)解决语音与文本的不定长关系,比如下图的隐马尔科夫模型中。
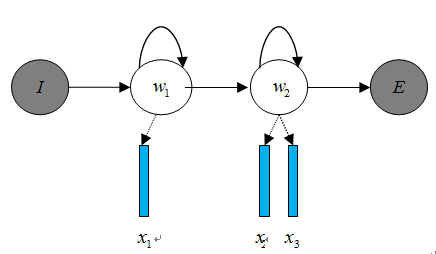
将声学模型表示为
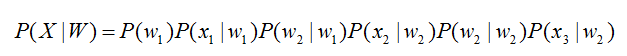
其中,初始状态概率和状态转移概率( 、 )可用通过常规统计的方法计算得出,发射概率( 、 、 )可以通过混合高斯模型GMM或深度神经网络DNN求解。
传统的语音识别系统普遍采用基于GMM-HMM的声学模型,示意图如下:
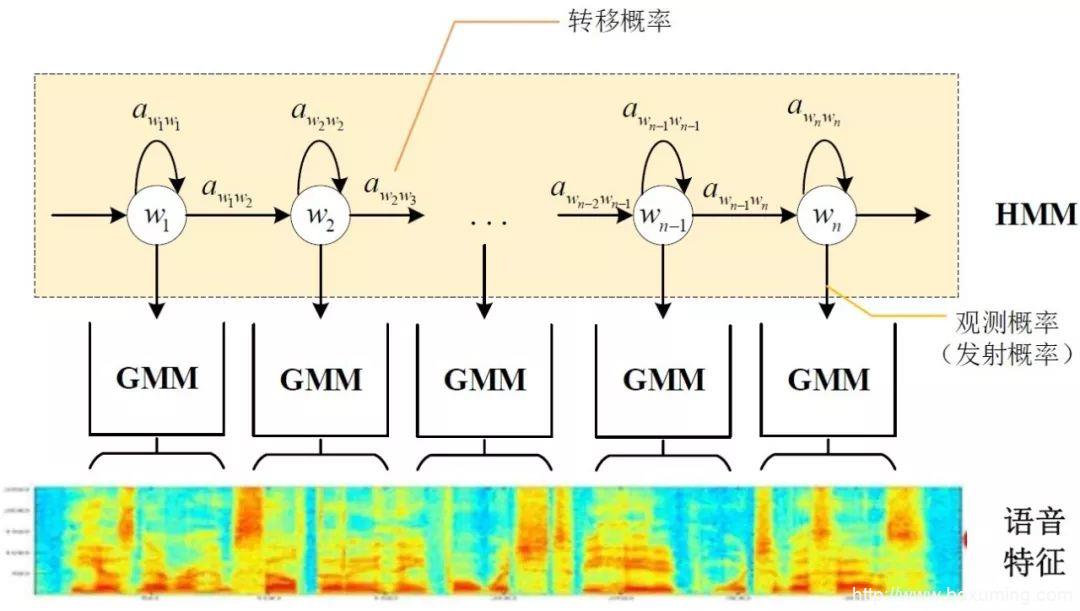
其中,表示状态转移概率,语音特征表示,通过混合高斯模型GMM建立特征与状态之间的联系,从而得到发射概率,并且,不同的状态对应的混合高斯模型参数不同。
基于GMM-HMM的语音识别只能学习到语音的浅层特征,不能获取到数据特征间的高阶相关性,DNN-HMM利用DNN较强的学习能力,能够提升识别性能,其声学模型示意图如下:
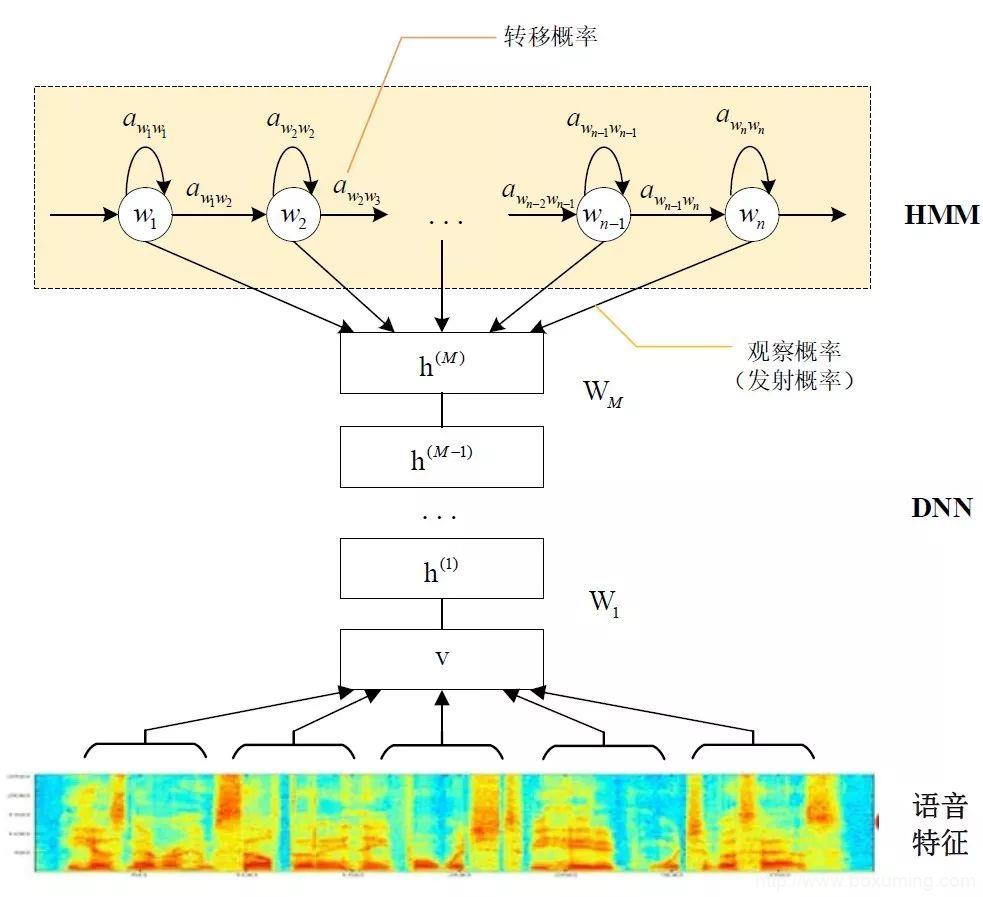
GMM-HMM和DNN-HMM的区别在于用DNN替换GMM来求解发射概率,GMM-HMM模型优势在于计算量较小且效果不俗。DNN-HMM模型提升了识别率,但对于硬件的计算能力要求较高。因此,模型的选择可以结合实际的应用调整。
4.语言模型
语言模型与文本处理相关,比如我们使用的智能输入法,当我们输入“nihao”,输入法候选词会出现“你好”而不是“尼毫”,候选词的排列参照语言模型得分的高低顺序。
语音识别中的语言模型也用于处理文字序列,它是结合声学模型的输出,给出概率最大的文字序列作为语音识别结果。由于语言模型是表示某一文字序列发生的概率,一般采用链式法则表示,如是由组成,则可由条件概率相关公式表示为:
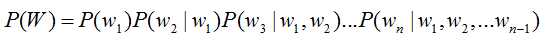
由于条件太长,使得概率的估计变得困难,常见的做法是认为每个词的概率分布只依赖于前几个出现的词语,这样的语言模型成为n-gram模型。在n-gram模型中,每个词的概率分布只依赖于前面n-1个词。例如在trigram(n取值为3)模型,可将上式化简:
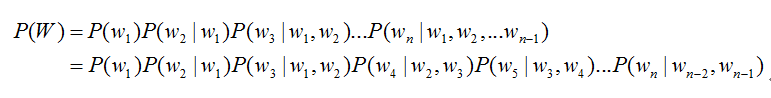
集道信息专业从事Polycom 宝利通视频会议/华为视频会议系统/ 东微智能产品,主要向客户提供远程视频会议系统、音视频系统、统一协作办公系统、服务器网络系统、数据中心机房系统、云计算数字办公系统、企业基础应用系统、展览展示舞台机械系统等行业解决方案。

